OpenAI的命門,決定了大模型公司的未來
作者|胡潤 來源|直面AI(ID:faceaibang)
如果Scaling Law是指導大模型能力提升最重要的標尺,那么“算力成本控制”就是大模型行業發展和商業化的基石。
年初DeepSeek在國外開源社區首先爆火,一個很重要的原因就是,DeepSeek幾乎將同性能模型的推理算力和訓練算力成本都降到了10%以內。MoE架構也在GPT-4發布之后,逐漸取代了稠密架構,成為了幾乎所有大模型開發商的默認選項,最核心的原因也是能夠有效降低模型推理的算力成本。
而OpenAI伴隨著GPT-5發布第一次與用戶見面的“路由(routing)”功能,設計本意也是代替用戶來把簡單問題匹配到低消耗模型,復雜問題匹配到能力和算力消耗高的推理模型,從而有效提升用戶體驗和算力效率,但卻變成AI圈最知名的“降本增笑”事件。
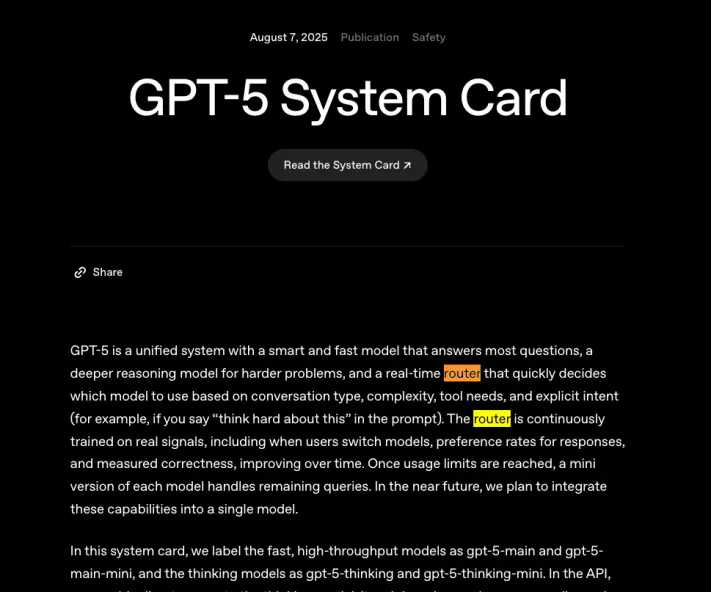
即便是GPT-5發布接近了一個月,OpenAI還是沒有能讓所有用戶滿意,網友依然還在吐槽,GPT-5沒有辦法解決一些很簡單的問題。雖然隨著OpenAI回滾了GPT-4o,還讓用戶能夠手動在推理模型和基本模型間切換,讓大多數用戶開始同意OpenAI宣稱的“GPT-5性能明顯強于之前的模型”,但是Sam Altman自己也沒有辦法否認,GPT-5的發布確實是漏洞百出。
而造成翻車最直接的原因,就是他們強推的路由功能沒有能夠將用戶的預期和相應的模型能力匹配好。
01
那么問題來了,為什么OpenAI要冒著GPT-5“發布即翻車”的風險,也要強推路由功能?
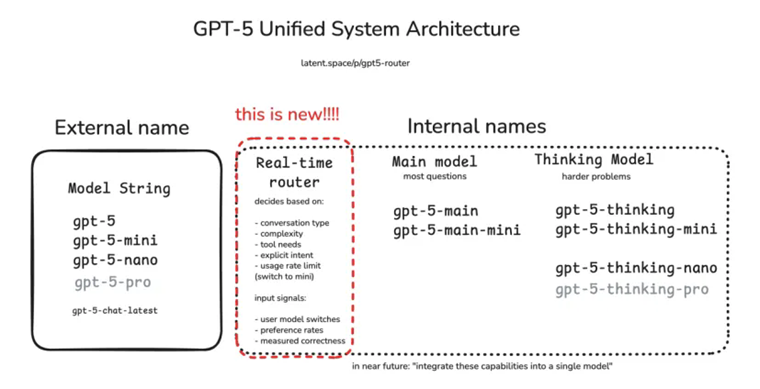
第一個最直接的原因就是,在GPT-5發布之前,OpenAI并行推出了5個以上的模型,讓用戶能夠根據自己需求來選擇合適的模型。隨著模型越來越多,別說普通用戶了,就是ChatGPT的重度用戶,有時候也很難決定使用哪個模型是最合適自己當前任務的。
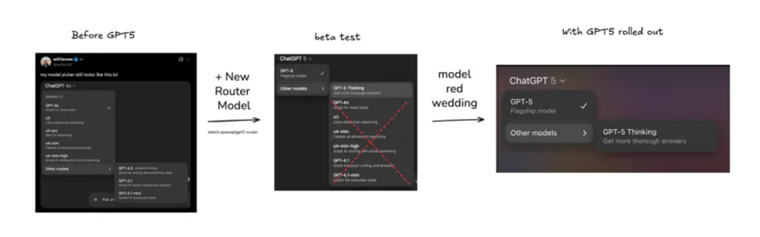
對于立志于將ChatGPT打造成為AI時代超級APP的OpenAI,不可能允許這樣的情況持續存在。特別是對于大量沒有接觸過大模型的普通用戶,替他們針對不同的任務選擇合適的模型,是OpenAI在某一個時間點必須要做的事情。
而另一個更深層次的原因在于,從算力成本的角度出發,自從推理模型出現之后,每一次對于大模型的詢問,都需要在推理模式和非推理模式之間進行一次選擇。而這種調配“深度思考”能力的效率,決定了大模型產品對于算力的使用效率。
根據學術界對于推理模型和非推理模型的研究結果,推理模型和飛推理模型的算力差異巨大,可能達到5-6倍。對于復雜問題,通過思維鏈等技術進行推理后內部消耗的推理token數可能高達上萬個。

而在延遲上,推理過程和非推理過程的差異就更加巨大了,根據OpenAI自己發布的數據,使用推理模型回答復雜問題所需要的時間,可能是使用非推理模型的60倍以上。
而就算對于很多需要復雜推理的任務在消耗了巨大的算力以及大量的時間之后, 之后給出的結果和準確性差異往往就在5%左右。為了這5%的性能提升,消耗多大的算力合適呢?

做一個簡單的算術題,如果OpenAI將所有任務都默認使用推理模型來完成,路由功能能夠幫助OpenAI識別出10%的問題可以通過簡單的非推理模型完成,就可能將算力成本降低8%(推理非推理算力比值為5:1)。
如果將這個比例進一步提高,能夠降低的算力成本將更加可觀。對于OpenAI這樣一個需要服務數億用戶,而且算力供應依然非常緊張的公司來說,路由功能是否能發揮作用可以說關系到自身商業模式是否可持續的核心能力。
在行業層面,第三方平臺(如 OpenRouter)把“自動路由與回退(fallback)”做成基建能力:當主模型擁塞、限流或內容拒絕時,按策略自動切換到次優模型,以穩定用戶體驗。微軟的Azure這樣的AI算力云供應商,也將不同模型之間的路由能力作為AI云計算的一大賣點。
也許,GPT-5發布之后,對于OpenAI來說最重要的事情就是在“質量-延遲-成本”的三角中尋找每條請求的最優平衡點。而目前官方對 GPT-5 的定位與“內置思考(built-in thinking)”敘事,實際上就是把“路由+推理強度”做成默認能力,并在 ChatGPT 端通過“Auto/Fast/Thinking”給了用戶一定程度的可見與可控性。
02
為大模型打造一個高效的路由功能到底有多難?
這個問題,外媒在一篇報道中向UIUC的一名計算機專業的助理教授求證,得到的回答是“可能是一個亞馬遜推薦系統級別的問題,需要大量專家努力工作數年時間才能獲得一個滿意的結果。”模型系統層面的路由功能本質是“多目標+強約束”的工程問題。 路由不是只拼準確率,還要在質量、延遲、成本、配額/峰值容量、成功率之間做實時優化。

而且從理論上來說,語義級別的路由功能在效率上來看,遠遠不是這問題的最優解。DeepSeek在上周放出的DeepSeek V3.1就在嘗試將推理模型和非推理模型混合起來,在一個更深層次上打造出一個效率更高的路由系統,從而從根本上提高大模型的“推理-非推理”的選擇效率。
根據網友體驗之后的感受,新的混合推理模型相比之前R1有著更快的思考速度:相較于 DeepSeek-R1-0528,DeepSeek-V3.1-Think 能在更短的時間內得出答案。
并且在回答性能相似的前提下,輸出長度有明顯的下降:新的推理模型在簡單問題上,推理過程有約10%以上的縮短。正式輸出的部分,新模型大幅精簡,平均僅有1000字,比R1 0528的平均2100字的水平提高了接近一倍。
但是另一方面,新的混合推理模型也爆出了一些不太穩定的問:比如會不時的在很多輸出中出現莫名其妙的“極”bug:答案中出現很多完全不相關的“極”。
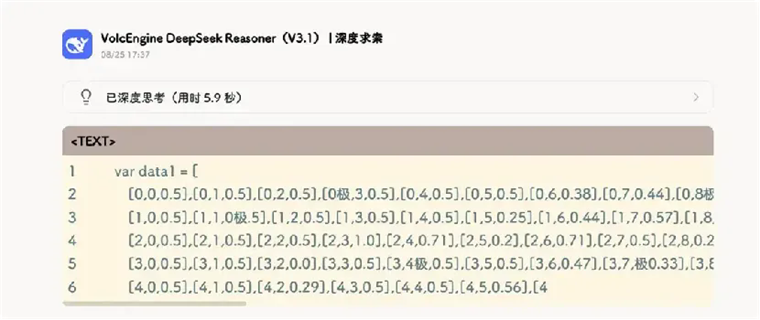
而且在R1上就存在的中英夾雜的情況似乎變得更加嚴重了,就像一個剛回國不久的留學生,在很多中文任務中會顯得很出戲。
即使像DeepSeek這樣的國內最頂尖的大模型團隊,將“推理-非推理”選擇功能內置到模型內部,模型的穩定性上也會出現一定程度的問題。而OpenAI和DeepSeek在自己各自首個推出的試圖高效調度“深度思考”能力的模型上都出現了不同程度的翻車,側面反應出要處理好這個問題的難度。
03
提高效率的另一面,是OpenAI依然處于對于算力的“極度渴求”的狀態中。
年初DeepSeekV3和R1的推出引發的全世界對于英偉達等算力供應商未來前景的擔憂,在短短幾個月之后就演變成了“AI成本悖論”——token單價下降但是模型的性能不斷成長,使得原本交由模型處理本來會顯得不經濟的任務也能交給大模型處理,模型能夠處理的任務將更多樣與復雜,從而會進一步推高token總量的需求。
OpenAI 正在推進代號Stargate的基礎設施擴張計劃:2025 年 7 月,OpenAI 與 Oracle 宣布在美國新增 4.5 GW 數據中心能力。

昨天,外媒也報道OpenAI 正物色印度當地合作伙伴,并計劃在新德里設立辦公室,把印度(其第二大用戶市場)的用戶增長與本地算力配置對接起來,在印度建設至少1Gw規模的數據中心。
“AI成本悖論”一方面不斷推高英偉達和AI云服務商的業績,同時也對像能夠有效降低模型算力需求的“路由”功能提出了更高的要求。
Sam Altman 反復強調“2025 年底上線的GPU 超過 100 萬片”的目標,且把長遠愿景瞄準“一億 GPU 量級”。這類表態從側面說明:即便推理單價在下降,更復雜的任務與更高的調用量讓大模型的“總賬單”并不會自動下降——必須靠路由把昂貴的推理時段“留給更需要的人”。
如果從大模型的第一性原理出發,所有大模型公司追求的最終極標準,就是不斷提升“算力兌換智力”的效率。而高效調度“深度思考”的能力,在推理大模型時代某種程度決定了大模型公司能否在系統和商業效率以及用戶體驗上領先全行業。
編者按:本文轉載自微信公眾號:直面AI(ID:faceaibang),作者:胡潤


本文作者信息
直面派(自媒體)
邀請演講廣告、內容合作請點這里:尋求合作
咨詢·服務